Introduction to Google BigTable
The database that powers core Google services like Search, Analytics, Maps, and Gmail.
It is a distributed storage system which is suitable for storing structured data. It resembles a relational database but has a different interface. It allows dynamic control over data layout and format. BigTable is designed to reliably scale to petabytes of data and thousands of machines. It has achieved several goals: wide applicability, scalability, high performance, and high availability. BigTable is used by more than sixty Google products and projects, including Google Analytics, Google Finance, Orkut, Personalized Search and Google Earth.
Data Model
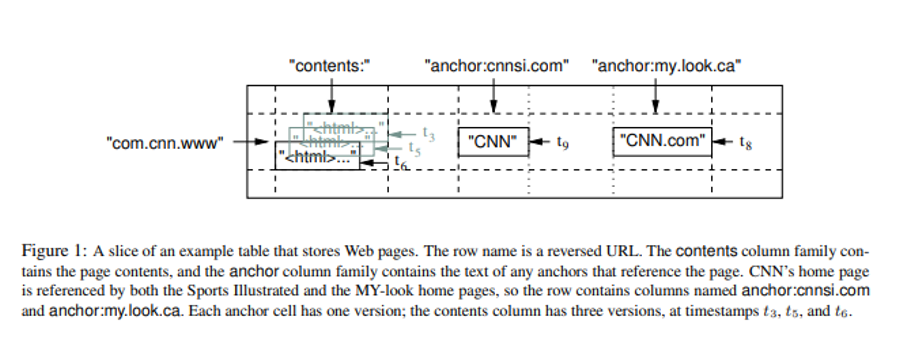
Considering the example of personalized search feature of Google: It is a service that records user clicks and queries across various parameters like web search, images, news etc. Trying to design it using SQL database system, We can have a table for all user IDs with websites visited at a particular timestamp. Even considering only a one-hour time span, the number of rows can be very large and it will be difficult for creating personalized search feature for a particular user. Now, trying to design it using NoSQL database system, We can have a document with key as user ID and in it we can have a JSON like array with weblink visited with anchors within the page and also the particular timestamp. But even with this upgradation, grouping of weblinks according to domain name or timestamps is an arduous task. Now using BigTable, we can have Each user has a unique userid and is assigned a row named by that userid. All user actions are stored in a table. BigTable maintains data in lexicographic order by row key. The row range for a table is dynamically partitioned. Each row range is called a tablet, which is the unit of distribution and load balancing. A tablet can be understood further using the example of a table that stores web pages: Each row entry is a separate URL. Pages in the same domain are grouped together into contiguous rows by reversing the hostname components of the URLs. For example, we store data for maps.google.com/index.html under the key com.google.maps/index.html. Column keys are grouped into sets called column families. A column key is named using the following syntax: family: qualifier. The qualifier is the name of the referring site; the cell contents is the link text. Access control and both disk and memory accounting are performed at the column-family level. A separate column family is reserved for each type of action (for example, there is a column family that stores all web queries, a column family that stores results for images searched etc). Each cell in a BigTable can contain multiple versions of the same data; these versions are indexed by timestamp. Each data element uses as its BigTable timestamp the time at which the corresponding user action occurred. Personalized Search generates user profiles using a MapReduce over BigTable. These user profiles are used to personalize live search results.
Implementation
The BigTable implementation has three major components: a library that is linked into every client, one master server, and many tablet servers. The master is responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, and garbage collection of files in GFS. In addition, it handles schema changes such as table and column family creations. Each tablet server manages a set of tablets (typically we have somewhere between ten to a thousand tablets per tablet server). The tablet server handles read and write requests to the tablets that it has loaded, and also splits tablets that have grown too large. A BigTable cluster stores a number of tables. Each table consists of a set of tablets, and each tablet contains all data associated with a row range. Initially, each table consists of just one tablet. As a table grows, it is automatically split into multiple tablets, each approximately 100-200 MB in size by default.